
# Spark 程序
Spark 程序用于执行 Spark 应用。
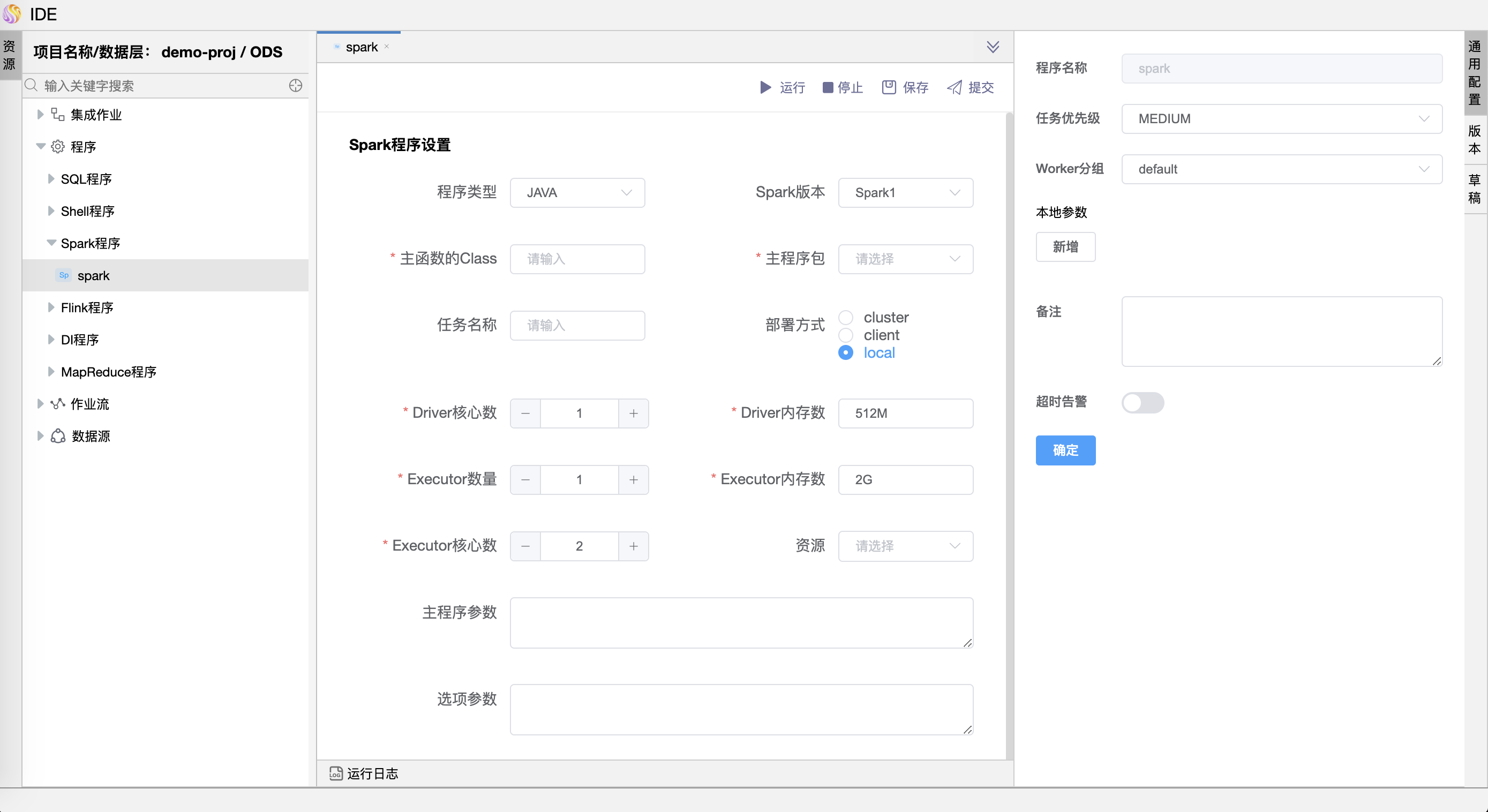
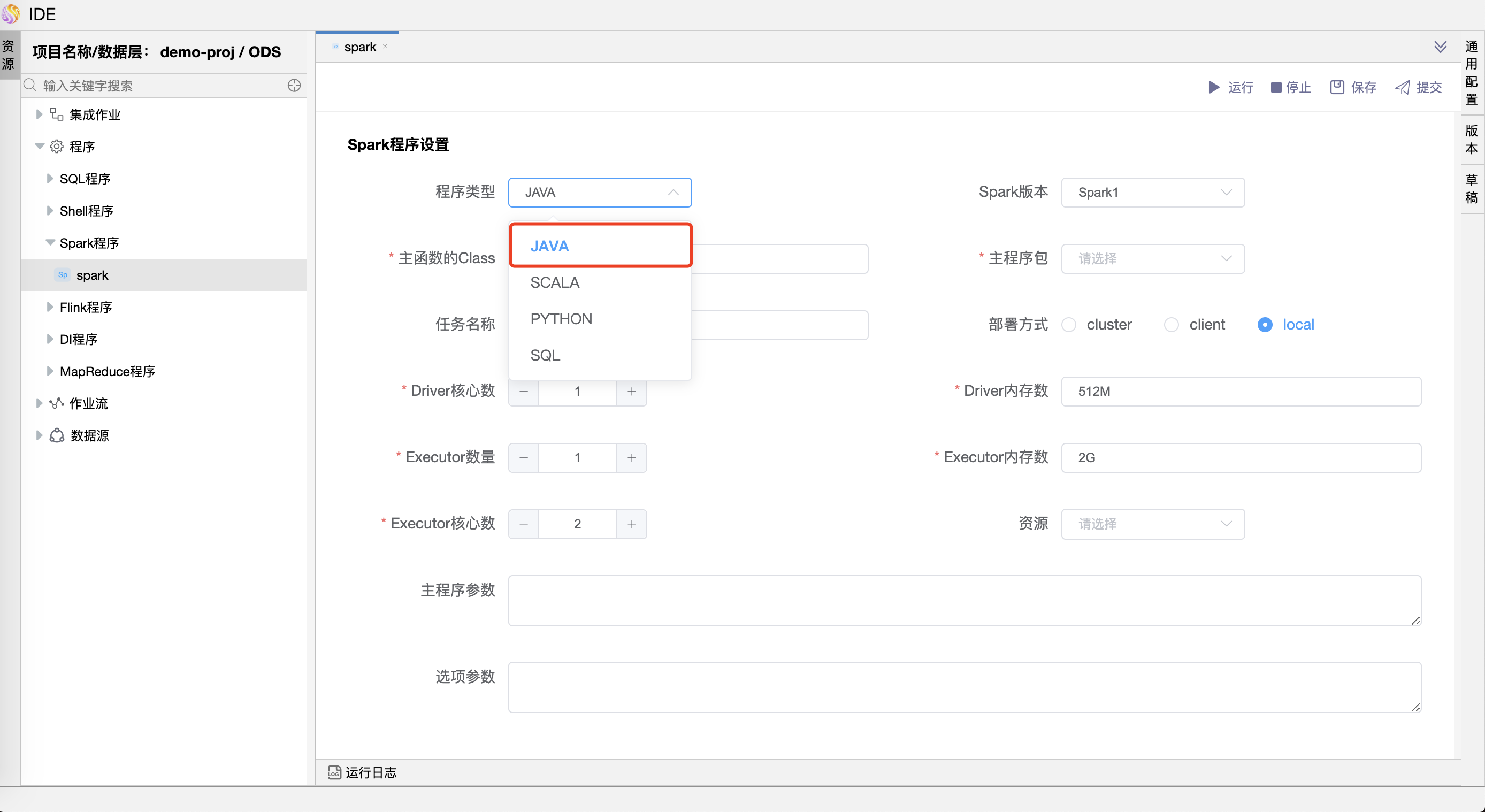
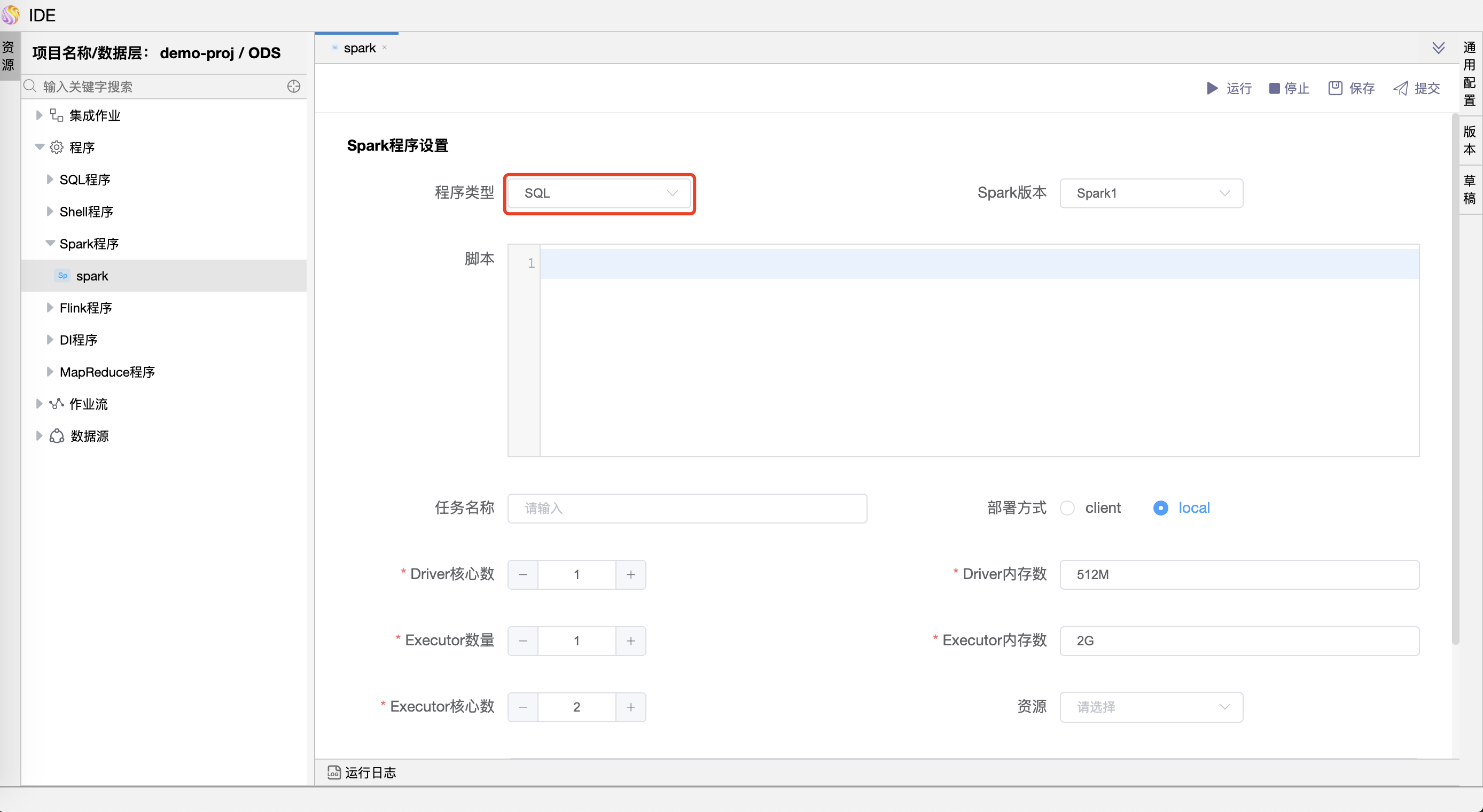
参数说明:
| 参数 | 说明 |
|---|---|
| 程序名称 | 设置程序的名称。一个作业流定义中的节点名称是唯一的。 |
| 任务优先级 | worker 线程数不足时,根据优先级从高到低依次执行,优先级一样时根据先进先出原则执行。 |
| Worker 分组 | 任务分配给 worker 组的机器执行,选择 Default,会随机选择一台 worker 机器执行。 |
| 本地参数 | 是 SHELL 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容。 |
| 超时告警 | 勾选超时告警、超时失败,当任务超过”超时时长”后,会发送告警邮件并且任务执行失败。 |
| 备注 | 描述该 Spark 程序的功能描述。 |
| 程序类型 | 支持 Java、Scala、Python 和 SQL 四种语言。 |
| Spark 版本 | 支持 Spark1 和 Spark2。 |
| 主函数的 Class | Spark 程序的入口 Main class 的全路径。 |
| 主程序包 | 执行 Spark 程序的 jar 包(通过项目配置》文件管理上传)。 |
| SQL脚本 | Spark sql 运行的 .sql 文件中的 SQL 语句。 |
| 部署方式 | (1) spark submit 支持 yarn-clusetr、yarn-client 和 local 三种模式。 (2) spark sql 支持 yarn-client 和 local 两种模式。 |
| 任务名称 | Spark 程序的名称。 |
| Driver 核心数 | 用于设置 Driver 内核数,可根据实际生产环境设置对应的核心数。 |
| Driver 内存数 | 用于设置 Driver 内存数,可根据实际生产环境设置对应的内存数。 |
| Executor 数量 | 用于设置 Executor 的数量,可根据实际生产环境设置对应的内存数。 |
| Executor 内存数 | 用于设置 Executor 内存数,可根据实际生产环境设置对应的内存数。 |
| 主程序参数 | 设置 Spark 程序的输入参数,支持自定义参数变量的替换。 |
| 选项参数 | 支持 --jar、--files、--archives、--conf 格式。 |
| 资源 | 如果其他参数中引用了资源文件,需要在资源中选择指定。 |
备注:
执行SPARK程序前,需要在${dolphinscheduler安装目录}/bin/env/dolphinscheduler_env.sh文件中,修改SPARK_HOME指向Spark服务在服务器中的路径。如export SPARK_HOME1=${SPARK_HOME1:-/home/spark/spark-2.4.0-bin-hadoop2.6}。