# 关系型数据库同步Hive数据示例
本示例主要演示从Mysql empsinfo表中读取数据,通过Replace组件进行字段配置,将Name中含KING的值替换为RANK,插入Hive empsinfo表中。
主要步骤如下:
# 准备数据
在Mysql中创建表empsinfo,在Hive中创建表empsinfo
Mysql表创建:
-- ---------------------------------------
-- Table structure for empsinfo_miggration
-- ---------------------------------------
DROP TABLE IF EXISTS `empsinfo`;
CREATE TABLE `empsinfo_miggration` (
`ID` int NOT NULL,
`NAME` varchar(10) DEFAULT NULL,
`AGE` decimal(3,0) DEFAULT NULL,
`EMPNO` int DEFAULT NULL,
PRIMARY KEY (`ID`)
);
-- ----------------------------
-- Records of empsinfo
-- ----------------------------
BEGIN;
INSERT INTO `empsinfo` (`ID`, `NAME`, `AGE`, `EMPNO`) VALUES (10001, 'WARD', 25, 7521);
INSERT INTO `empsinfo` (`ID`, `NAME`, `AGE`, `EMPNO`) VALUES (10002, 'JONES', 32, 7566);
INSERT INTO `empsinfo` (`ID`, `NAME`, `AGE`, `EMPNO`) VALUES (10003, 'BLAKE', 15, 7698);
INSERT INTO `empsinfo` (`ID`, `NAME`, `AGE`, `EMPNO`) VALUES (10004, 'SCOTT', 53, 7788);
INSERT INTO `empsinfo` (`ID`, `NAME`, `AGE`, `EMPNO`) VALUES (10005, 'KING', 22, 7839);
COMMIT;
Hive表创建:
-- ---------------------------------------
-- Table structure for empsinfo
-- ---------------------------------------
DROP TABLE IF EXISTS `empsinfo`;
CREATE TABLE `empsinfo` (
`ID` int ,
`NAME` String ,
`AGE` int,
`EMPNO` int
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS ORC;
INSERT INTO `empsinfo` VALUES (10001, 'WARD', 25, 7521);
INSERT INTO `empsinfo` VALUES (10002, 'JONES', 32, 7566);
INSERT INTO `empsinfo` VALUES (10003, 'BLAKE', 15, 7698);
INSERT INTO `empsinfo` VALUES (10004, 'SCOTT', 53, 7788);
INSERT INTO `empsinfo` VALUES (10005, 'KING', 22, 7839);
# 新建同步作业
点击数据同步上的【...】,选择弹出菜单【新建数据同步作业】,作业名称为:JDBCSource-Replace-HiveSink。
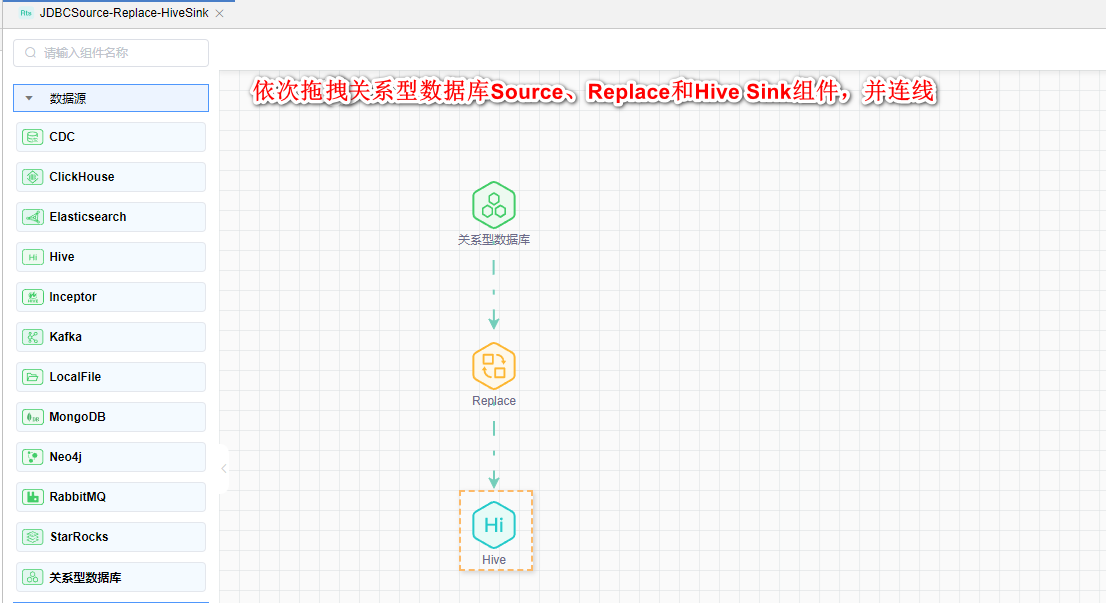
# 拖拽图元
依次拖拽数据源中的JDBC Source组件、转换中的Replace组件和目标中的Hive Sink组件,依次连线。如下图所示:
# 配置组件属性
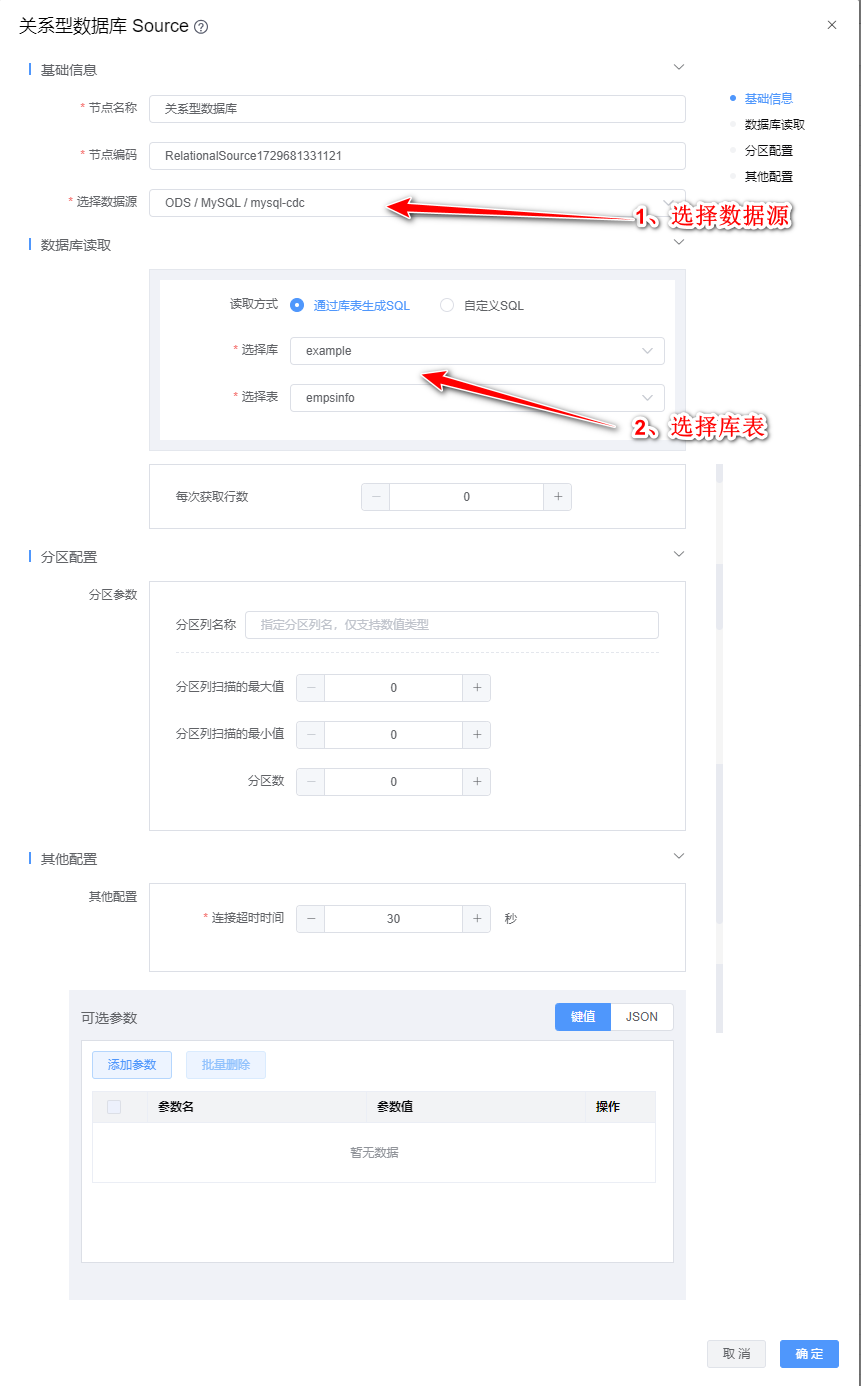
1、双击"JDBC Source"组件,根据下图所示步骤依次配置。
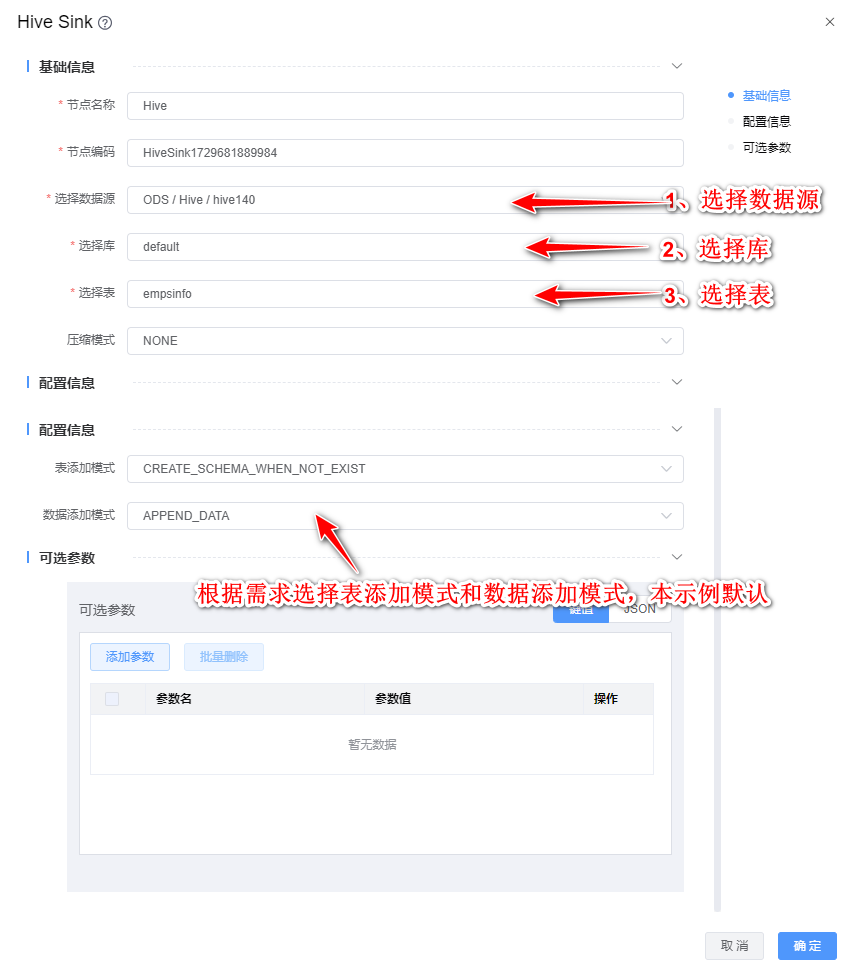
2、双击"Hive Sink"组件,根据下图所示步骤依次配置。
3、双击"Replace"组件,根据下图所示步骤依次配置。
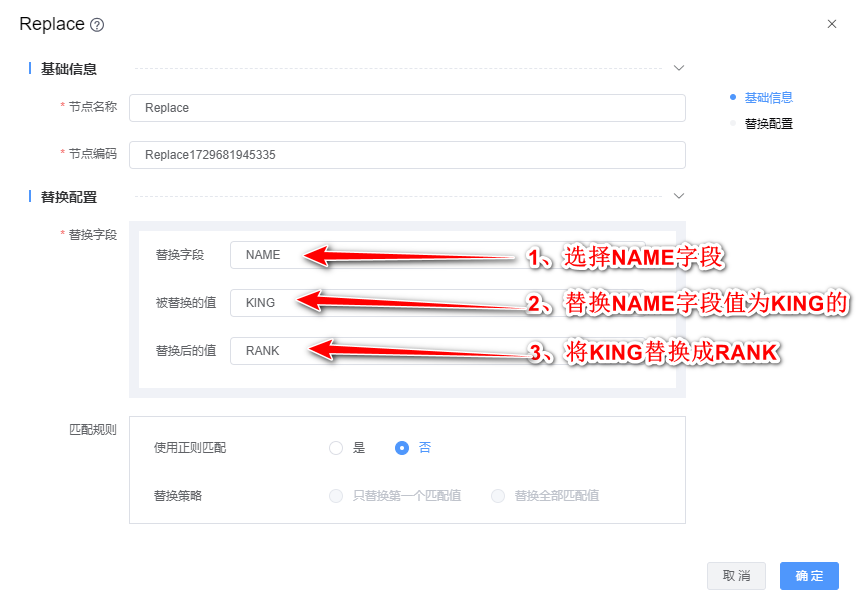
4、Ctrl+S保存该模型。
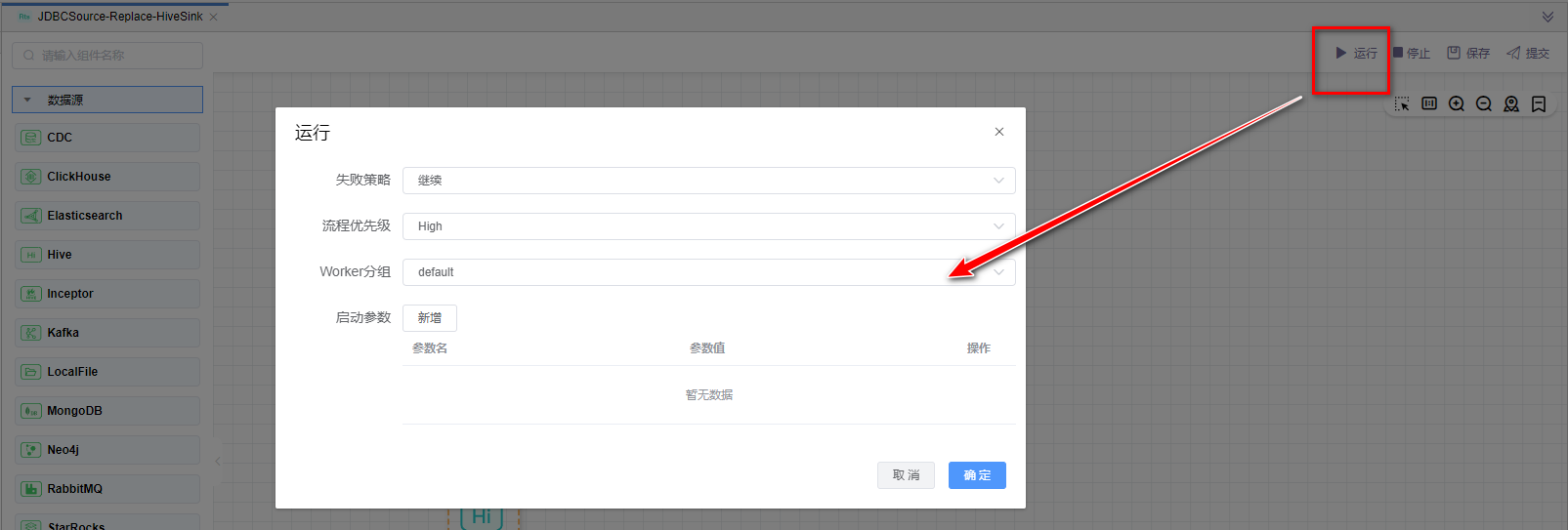
# 运行
点击【运行】按钮,可以运行已经开发完毕的场景,在日志栏可以看运行日志及运行结果。
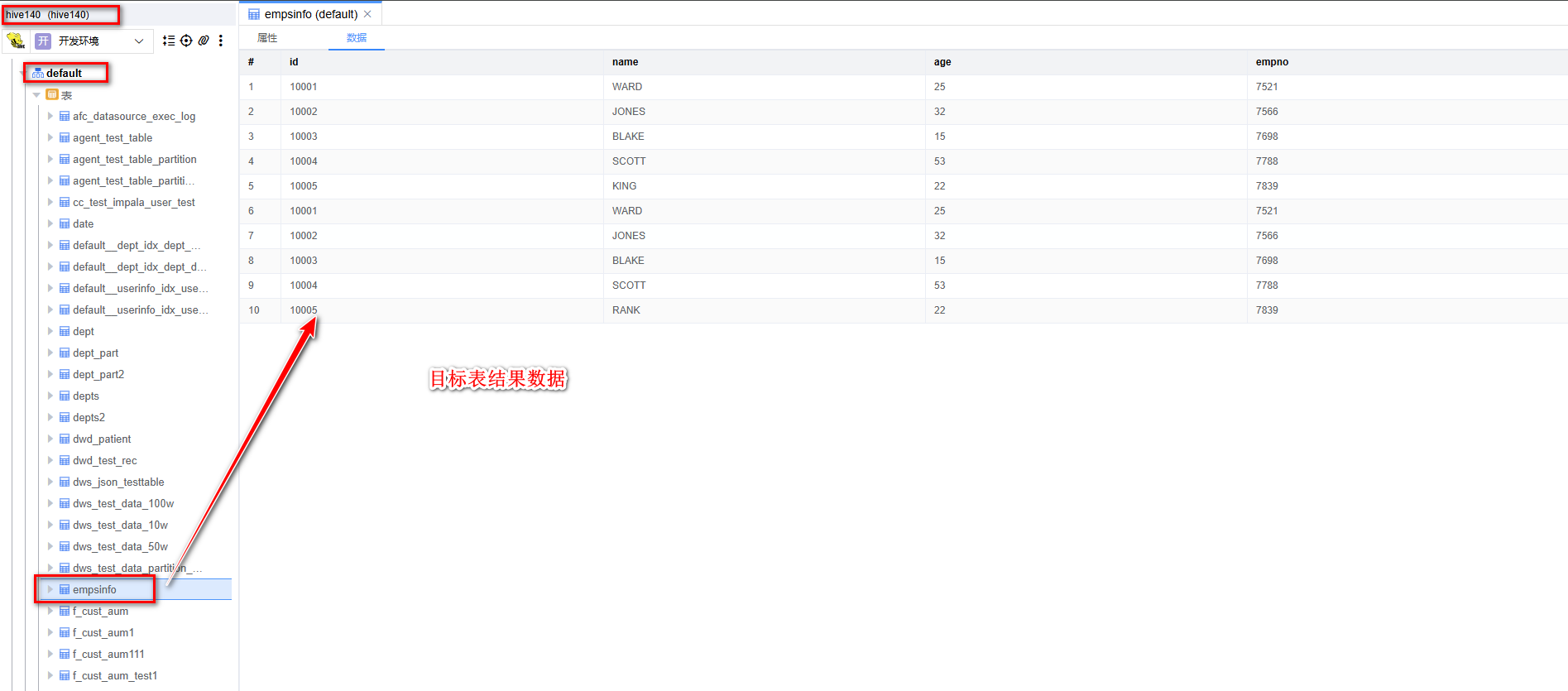
# 查看数据
从SQL客户端中去目标表查看 empsinfo 源表数据已经同步到 empsinfo 目标表中。
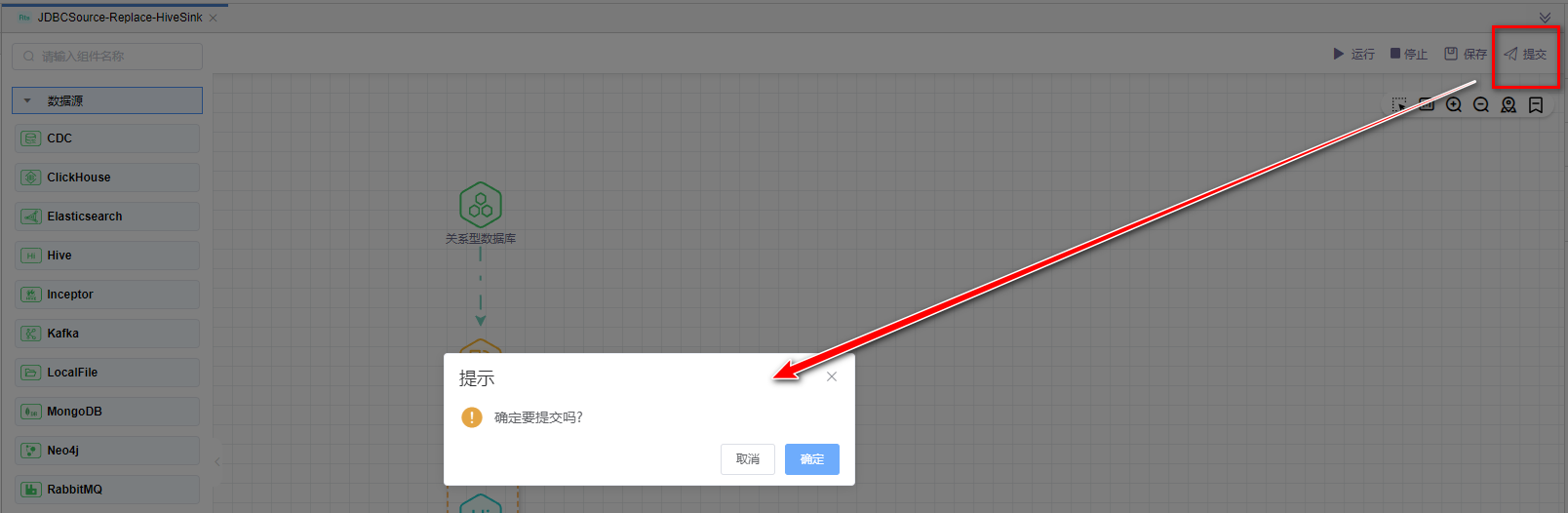
# 提交版本
当草稿运行正常后,点击【提交】按钮可以将该版本提交到作业调度,每次修改提交都会生成新的版本,可以看到提交的历史版本,并可以随意切换版本。
提交后的版本,可以在作业调度中进行"定时"调度配置。